Fiquei pensando um bom tempo em porque
certas pesquisas erram. E isto acontece de modo mais claro durante eleições.
Se olharmos as pesquisas, há uma série de suposições envolvidas para evitar o
erro sistemático. Não estou supondo que há ou não viés nas mesmas. Pode até haver, mas é pouquíssimo provável que
haja o mesmo viés em todas elas.
Então, pensei em um modelo que ajudasse a entender o que poderia estar acontecendo. O modelo se baseia em que a pesquisa tenta descobrir o valor médio de uma grandeza na população X através de uma amostragem. A amostragem introduz uma incerteza, que é modelada como uma
variável aleatória normal û de média zero e
desvio padrão definido pelo tamanho da amostra.
Então o que temos é
Y = X+û. O valor obtido pela amostragem teria como centro
X com um intervalo de confiança definido pelas estatísticas de
û. A suposição de média zero é importante, pois indica que não há erros sistemáticos ocorrendo aqui. Efetivamente, no caso de uma eleição, a grandeza
X é a probabilidade de voto de um eleitor aleatoriamente escolhido em um determinado candidato
Y ao invés do candidato
W. Portanto
p(vota em Y) = X
Mas na realidade, como estamos esta é uma pesquisa, não obtemos
p(votar em Y), mas
p(diz votar em Y). Portanto, então temos que considerar a probabilidade completa. Originalmente temos:
p(diz votar em Y) = p(diz votar em Y| vota em Y)*p(vota em Y)
E intrinsecamente supõe-se que
p(diz em vota em Y | vota em Y) =1. Mas na realidade, o que pode ocorrer é (e suspeito que ocorre):
p(diz votar em Y) = p(diz votar em Y| vota em Y)*p(vota em Y) + p(diz votar em Y | vota em W)* p(vota em W).
Notem que aqui surgem uma segunda variável aleatória que pode alterar o resultado da pesquisa. Vamos a um exemplo mais prático. Em São Paulo, a
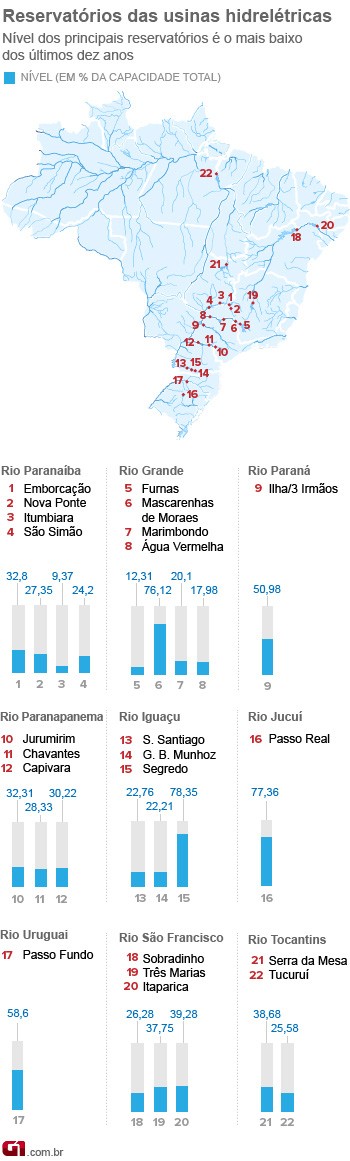
última pesquisa datafolha apontou os seguintes resultados para o primeiro turno: 28% para José Serra, 27% para Russomano, 24% para Haddad, 13% para Chalita, 5% para Soninha. A última do Ibope também não foi muito diferente: 26% para José Serra, 26% para Russomano, 26% para Haddad, 13% para Chalita, 5% para Soninha. Note que tudo dentro dos 2%(Datafolha) e 3% (Ibope) de margem que geralmente é usada.
Mas o que aconteceu? Na eleição, o resultado foi: 30.75% para José Serra, 21.6% para Russomano, 28.98% para Haddad, 13.6% para Chalita, 2.65% para Soninha. Note que há um desvio considerável do resultado final para o projetado. Minha suposição é que ouve um efeito do tipo:
p(diz votar em Y) = p(diz votar em Y| vota em Y)*p(vota em Y) + p(diz votar em Y | vota em W)* p(vota em W)+p(diz votar em Y | vota em Z)* p(vota em Z)+p(diz votar em Y | vota em V)* p(vota em V).
Por exemplo:
p(diz votar em Haddad) = p(diz votar em Haddad| vota em Haddad)*p(vota em Haddad) + p(diz votar em Haddad | vota em Serra)* p(vota em Serra)+p(diz votar em Haddad| vota em Russomano)* p(vota em Russomano)+p(diz votar em Haddad| vota em Chalita)* p(vota em Chalita)+p(diz votar em Haddad| vota em Soninha)* p(vota em Soninha).
Uma vez tendo este resultado para todos os candidatos, em tese seria possível desacoplar os resultados em partes específicas. Mas o problema é que o sistema é indeterminado, por exemplo:
0.24 = p(diz votar em Haddad| vota em Haddad)*0.2898 + p(diz votar em Haddad | vota em Serra)* 0.3075+p(diz votar em Haddad| vota em Russomano)* 0.216+p(diz votar em Haddad| vota em Chalita)* 0.136+p(diz votar em Haddad| vota em Soninha)* 0.0265.
Poderíamos simplificar dessa forma:
0.24 = p(diz votar em Haddad| vota em Haddad)*0.2898 + p(diz votar em Haddad | não vota em Haddad)* 0.7102 (no caso Datafolha)
0.26 = p(diz votar em Haddad| vota em Haddad)*0.2898 + p(diz votar em Haddad | não vota em Haddad)* 0.7102 (no caso Ibope)
As duas equações são idênticas dentro da margem de erro das pesquisas. Então como descobrir? Ainda estou trabalhando nisso, mas suspeito que aqui podemos ter uma explicação para parte dos problemas com as pesquisas eleitorais.
Por que as pessoas falariam uma coisa e fariam outra? Bem, o que o leitor acha?